
 Last June, Microsoft introduced AI Builder, which is an artificial platform that can be integrated in a Power Platform low-code application. It is still in preview, and since that day, I wanted to give it a try and find an interesting use case to test these new features.
Last June, Microsoft introduced AI Builder, which is an artificial platform that can be integrated in a Power Platform low-code application. It is still in preview, and since that day, I wanted to give it a try and find an interesting use case to test these new features.
In the context of automation of office document and application processing, AI has perfectly its place and we can see that Microsoft is making important investments in that area.
The use case I took for this post is to automate the processing of request forms in order to extract the data from them and to use them as metadata in SharePoint. Of course, these metadata could directly be used to make decision or to go further in the processing of a request, but let’s keep simple first.
Thus, the steps are :
- Get the file
- Analyze the file and extract the data
- Upload the file in SharePoint
- Update the file with the metadata
This post and the next one will then guide through the steps to create this flow
Create a Form Processing Model
The first thing to do is to create a Form Processing model that will be used later (in the next post) by the Flow.
At the time this post is written, Microsoft proposes 4 models ready to be used :
- Form Processing to read and process documents or forms
- Object Detection to analyze images
- Prediction in order to give an idea of what will happen, based on past data
- Text classification in order to analyze its meaning or even make sentiment analysis
The starter model to use in this case is of course the Form Processing one.
These models are premium features, which means that you’ll probably have to activate them or start a 30-days trial period. Unfortunately, after the 30 days of trial, it seems that the models wouldn’t be usable anymore
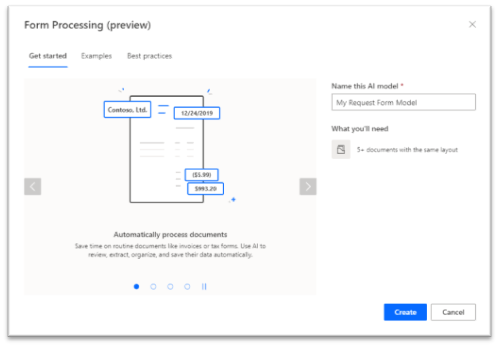
Creating a Form Processing model is done in several steps, but before starting the creation of the model, you will need a minimum of 5 forms to train it. It is expected that the forms have the same layout. Indeed, the model will try to identify the zones were the data is, therefore, these data must be in the same locations on the form. An advantage is that it is also able to identify zones where hand-written inputs are present. In other words, the OCR seems working pretty well.
If the forms are already available, when starting the wizard, the very first step of the Form Processing model creation is simply to give it a name. At this stage, there are also some explanations of the constraints for the model to work, like the one mentioned just before about the layout.
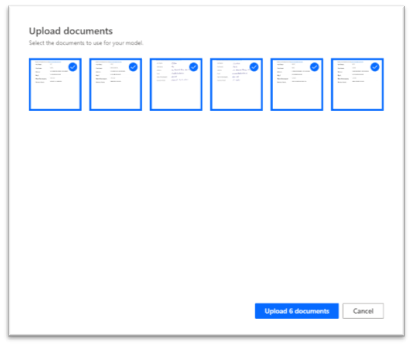
The next step asks to upload the minimum 5 forms that will be used to identify the zones where the data is. To have a better result, I would advise to use the best forms available, in terms of clarity, contrast, etc, which would help the model in the identification of the interesting zones.
After this step, there is still a way to upload other samples of the forms, but the limit is set to a total upload of 4MB. This limit, for the time being, seems a bit low, but, with 5 or 6 documents, the results are already good. According to this post, it is a feature that will be improved.
The next step is the analysis of the uploaded documents that will lead to the selection of the fields we want to get from the forms.
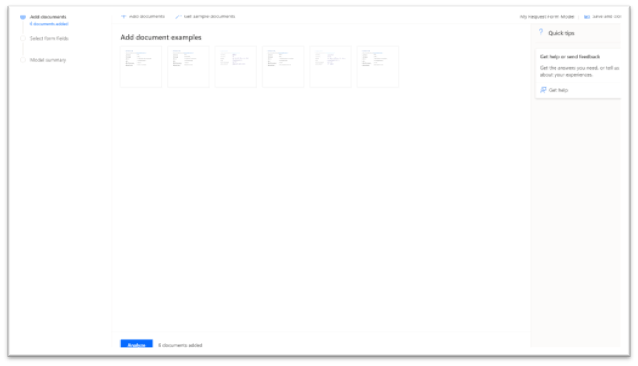
It shows one of the uploaded forms, with the discovered zones of data and a percentage of accuracy estimated by the model. As the example shows, almost all the fields have been correctly identified, except the first one, where the zone is a bit too large.
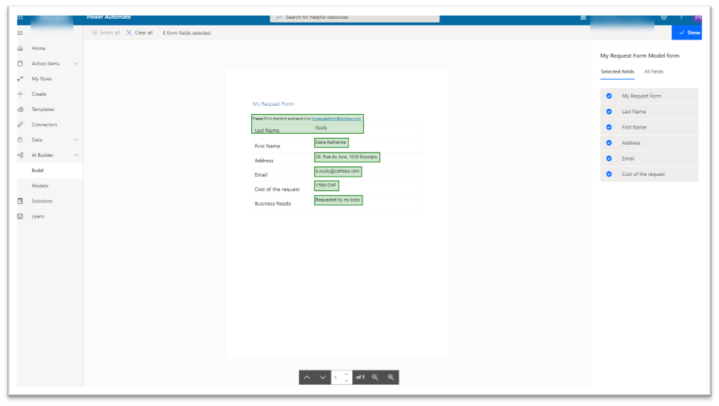 Here, I would make one suggestion of improvements : either we should be able, at this stage, to come back to upload additional samples or at this stage, or, to be able manually to resize the zones. This is important, because having a zone too large will make the extraction of data less accurate (we will see what it means later in the second post). Apparently, this is something that will come.
Here, I would make one suggestion of improvements : either we should be able, at this stage, to come back to upload additional samples or at this stage, or, to be able manually to resize the zones. This is important, because having a zone too large will make the extraction of data less accurate (we will see what it means later in the second post). Apparently, this is something that will come.
In addition to selecting the fields, we can give and change the names of these fields.
Once this is done, we are back to the list of models we have created, and what remains to be done is to make our model available for use. This step is called publishing. A click on the model will allow us to either make a quick test by uploading a form sample, or to publish it.
Here, I would also have a to be able to update the model, for example after having improved it and to be able to publish further versions of the model.
As we can see, creating a model to process forms is quite easy, thanks to the AI in the background, making these capabilities at our fingertips. It is still in preview and no doubts they will be perfectioned in a near future, but it shows that automation is something taken seriously at Microsoft. The process of creating a model and how it can be used in Flow is really easy and makes it accessible also for the users that don’t have too much technical knowledge in artificial intelligence.
We will see in the next post how to use it in Flow, in order to automate the processing of PDF documents.
0 Comments