
In the previous post, we saw how to create and train a Form Processing model, a tool released in preview last June and available in the AI Builder box of Power Automate.
In this second post, we are going to use that model in a Flow, so that it will take files from a specific repository, analyze and extract data from it, and store it in a final location associated with the extracted data
The source where the files will be picked up is going to be a OneDrive folder whereas, on the other end, the destination will be a SharePoint Online document library.
As such, in this post we will :
- Create a SharePoint Online document library able to store the file’s metadata
- Create the Flow
- Test the end-to-end scenario
From the previous post, the following document properties will have to be stored, and thus, the corresponding columns in the document library (for simplicity, all of them are going to be a “Single Line of Text” type of property) :
- Last Name
- First Name
- Address
- Cost
- Reason

For the source, just create a OneDrive for Business folder.
Create a Power Automate Flow
Switch to Power Automate and create a new solution, or use an existing one, give it a name, select a publisher and set its version (all these properties are mandatory). In fact, AI Builder models can only be used from within a solution-aware Flow (reference here).
Once in the selected, or created, solution, we can add a new Flow.
As a trigger, we select the “When a file is created” from the “OneDrive for Business” category. It needs to have the permissions to read the files in the configured directory, thus, credentials may be asked to get access to the folder.
This trigger will thus launch the Flow whenever a new file arrives in this folder.
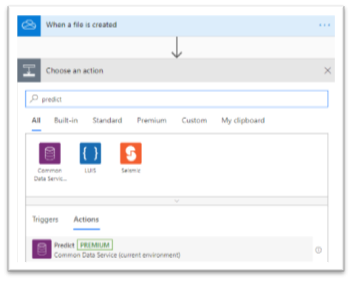
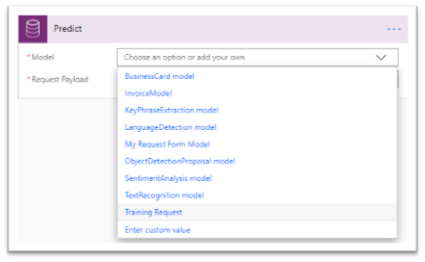
When the Flow gets the file, it is time to use the model created in the previous blog post. Let’s select the “Predict” action from the “Common Data Service” group, we can see that it is indeed a Premium feature. In the configuration of the “Predict” action, we can now select the model we have built and named, in this case, “My Request Form Model”. For the “Request Payload” JSON parameter, we have to take the content of the HTTP request’s body, which gives the following :
{
“base64Encoded”: “string(triggerBody()?[‘$content’])”,
“mimeType”: “application/pdf”
}
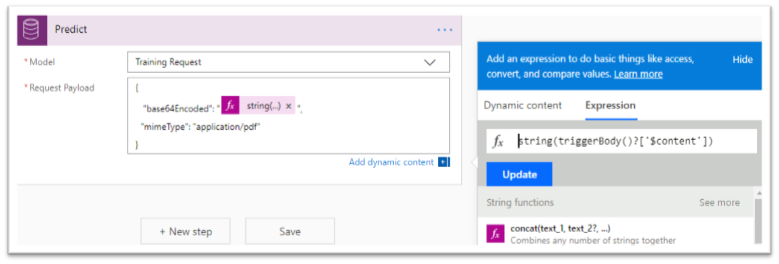
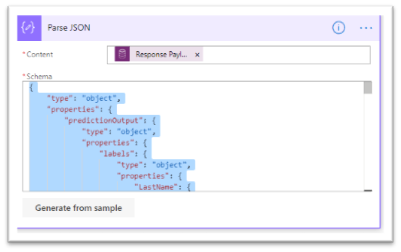
The call to the model will return a JSON response that requires to be parsed. Obviously, we should use the “Parse JSON” action to extract the different value from the response. But, for this, we must specify the schema, and the best way to get it is to provide an example of the data returned by “Predict”.
We can have such response by saving the Flow as it is now, and to test it. Let’s click on “Test” and using an example of a form to be dropped in the OneDrive folder. After several seconds, the Flow will run, and hopefully, succeed. If we click on the execution history, we can see the different inputs and outputs for all the executed actions. Then, if we take the “Predict” action, we can copy the “Output” of it in the clipboard.
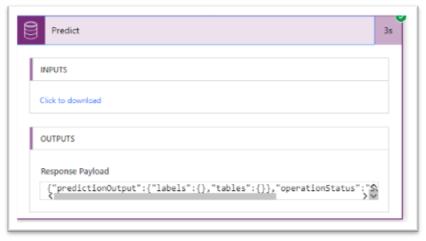
Now, we go back to the edition of our Flow, and add the “Parse JSON” action, set the “Response Payload” as a “Content” parameter.
For the “Schema”, we click on the “Generate from sample” which will pop-up a window where we can paste what we have in the clipboard. After clicking the “Done” button, the “Schema” parameter is filled.
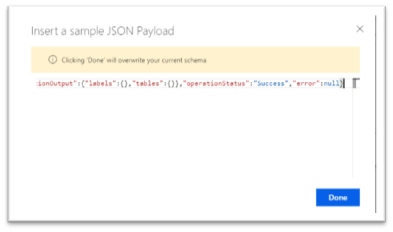
Everything should be fine would we say.
But, unfortunately not. It happens that the schema generator is misleading by the data we give to it. A typical example is the “confidence” value. If all your fields during the analysis of the model returned 100% of confidence, it means the data returned will be equal to “1”. The consequence is that the schema generator will interpret it as an integer, which is wrong. It is enough that once the model returns a confidence of less than 100% to prevent any schema validation. So, it is necessary to replace all confidence fields of type integer by number, to be safe.
We are done with the “Parse JSON”, now, let’s create the file.
For that, we will use the “Create file” action from the “SharePoint Online” group, then we select the “Site Address”, the “Folder Path” (which is nothing but the target document library), and we set the “File Name” and “File Content” parameters to the corresponding attributes of the source file.
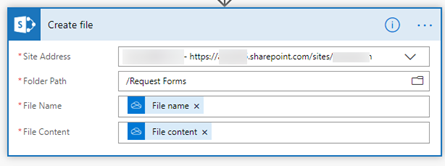
This action can’t update the properties of the file, leading us to add another action called “Update file properties” from the same “SharePoint Online” group.
As for the previous action, the “Site Address” and the “Library Name” must be set, but rather than specifying the file name, we have to use the “ItemId” from the previous action to define the file that needs to be updated. The columns added to the library are automatically present as parameters of the action, but the difficulty here is to find the right “value” to set in each of these fields. There is apparently a bug as the value selector only displays the “value” attribute’s name, which is “value”, instead of taking the parent attribute name that would be “LastName”, “FirstName” and so on. Nevertheless, before picking randomly a value and hoping for the best, we can make a quick check once we have picked a dynamic field. By hovering the “value” field with the mouse, a tip is popping up, displaying the complete expression, containing the real attribute name (here “LastName”).
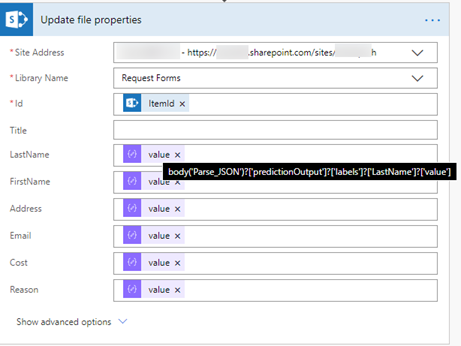
Finally, once all these file attributes are set, it is time to save the Flow, and test it. Just drop an PDF form in the OneDrive for Business folder, wait for some seconds or minutes, and the file should appear in the SharePoint Online document library with the correct metadata. Or, almost.
As can be seen in the screenshot, the LastName property is not well extracted, and this comes back to my first suggestion for improvement where the field zone should be manually adjustable to resize the location where the data can be. In this case, we could see that the “LastName” zone was far too large, leading to a property that is not only containing the name, but also part of the form instructions.
But, otherwise, we can see that the document has the correct properties taken from the content of the PDF.

0 Comments